Supercomputer architecture
Configuration of Irene
The compute nodes are gathered in partitions according to their hardware characteristics (CPU architecture, amount of RAM, presence of GPU, etc). A partition is a set of identical nodes that can be targeted to host one or several jobs. Choosing the right partition for a job depends on code prerequisites in term of hardware resources. For example, executing a code designed to be GPU accelerated requires a partition with GPU nodes.
The Irene supercomputer offers three different kind of nodes: regular compute nodes, large memory nodes, and GPU nodes.
- AMD Rome nodes for regular computation
Partition name : Rome
CPUs: 2x64 AMD Rome@2.6Ghz (AVX2)
Core/Node: 128
Nodes: 2286
Total core: 292 608
RAM/Node: 228GB
RAM/core : 1.8GB
- Fat nodes with a lot of shared memory for computation lasting a reasonable amount of time and using no more than one node
Partition name: xlarge
CPUs: 4x28-cores Intel Skylake@2.1GHz
GPUs: 1x Nvidia Pascal P100
Cores/Node: 112
Nodes: 5
Total cores: 560
RAM/Node: 3TB
RAM/Core: 27GB
IO: 2 HDD de 1 TB + 1 SSD 1600 GB/NVMe
- V100 nodes for GPU computing and AI
Partition name: V100
CPUs: 2x20-cores Intel Cascadelake@2.1GHz (AVX512)
GPUs: 4x Nvidia Tesla V100
Cores/Node: 40
Nodes: 32
Total cores: 1280 (+ 128 GPU)
RAM/Node: 175 GB
RAM/Core: 4.4 GB
- V100l nodes for GPU computing and AI
Partition name: V100
CPUs: 2x18-cores Intel Cascadelake@2.6GHz (AVX512)
GPUs: 1x Nvidia Tesla V100
Cores/Node: 36
Nodes: 30
Total cores: 1080 (+ 30 GPU)
RAM/Node: 355 GB
RAM/Core: 9.9 GB
- V100xl nodes for GPU computing and AI
Partition name: V100
CPUs: 4x18-cores Intel Cascadelake@2.6GHz (AVX512)
GPUs: 1x Nvidia Tesla V100
Cores/Node: 72
Nodes: 2
Total cores: 144 (+ 30 GPU)
RAM/Node: 2.9 TB
RAM/Core: 40 GB
Note that depending on the computing share owned by the partner you are attached to, you may not have access to all the partitions. You can check on which partition(s) your project has allocated hours thanks to the command ccc_myproject.
ccc_mpinfo displays the available partitions/queues that can be used on a job.
$ ccc_mpinfo
--------------CPUS------------ -------------NODES------------
PARTITION STATUS TOTAL DOWN USED FREE TOTAL DOWN USED FREE MpC CpN SpN CpS TpC GpN GPU Type
--------- ------ ------ ------ ------ ------ ------ ------ ------ ------ ------ ---- --- ---- --- --- --------
rome up 291584 128 289170 2286 2278 1 2271 6 1781 128 8 16 2 0
v100 up 1280 0 1200 80 32 0 31 1 4375 40 4 10 2 4 nvidia
v100l up 1080 0 1080 0 30 0 30 0 9861 36 2 18 2 1 nvidia
v100l-os up 1080 0 1080 0 30 0 30 0 9861 36 2 18 2 1 nvidia
xlarge up 560 0 404 156 5 0 5 0 26803 112 4 28 1 1 nvidia
v100xl up 144 0 0 144 2 0 0 2 40277 72 4 18 2 1 nvidia
MpC : amount of memory per core
CpN : number of cores per node
SpN : number of sockets per node
Cps : number of cores per socket
TpC : number of threads per core This allows for SMT (Simultaneous Multithreading, as hyperthreading for Intel architecture)
Interconnect
The compute nodes are connected through a EDR InfiniBand network in a pruned FAT tree topology. This high throughput and low latency network is used for I/O and communications among nodes of the supercomputer.
Lustre
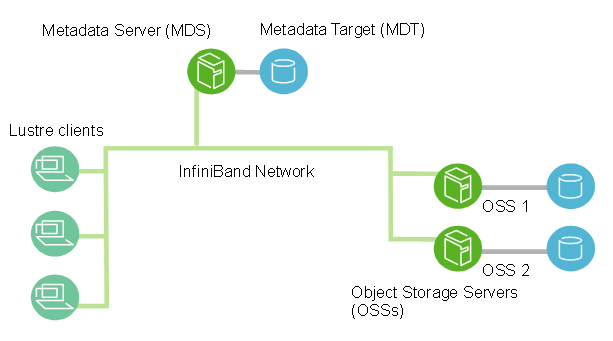
Lustre is a type of parallel distributed file system, commonly used for large-scale cluster computing. It actually relies on a set of multiple I/O servers and the Lustre software presents them as a single unified filesystem.
The major Lustre components are the MDS and OSSs. The MDS stores metadata such as file names, directories, access permissions, and file layout. It is not actually involved in any I/O operations. The actual data is stored on the OSSs. Note that one single file can be stored on several OSSs which is one of the benefits of Lustre when working with large files.
Lustre
More information on how Lustre works and best practices are described in Lustre best practice.